OpenAI的內(nèi)部推理模型,又拿下了IOI 2025金牌,打敗325名人類選手,總排名第6,AI組第1。該模型沿襲IMO金牌版別,無專門練習(xí),限時5小時、50次提交且無聯(lián)網(wǎng)支撐。
剛剛,OpenAI內(nèi)部推理模型在取得IMO金牌后,又拿下了IOI金牌。
和前次IMO相同,OpenAI 運用了草莓形象來代表這個推理模型。
只不過這次的「草莓」不只帶上了IOI的金牌,而且愈加的擬人,這個形象很有或許進化為OpenAI內(nèi)部推理體系代表形象。

OpenAI宣言的這個「內(nèi)部推理體系」便是前次拿下IMO金牌,惹出爭議的同款模型。
IMO之后,OpenAI對IMO金牌模型進行了全面評價,發(fā)現(xiàn)除了數(shù)學(xué)比賽之外,它在許多其他范疇(包含編程)也是現(xiàn)在最好的模型。
因而,OpenAI決議直接運用完全相同的IMO金牌模型,不做任何更改,并將其使用于IOI的體系中。

OpenAI官方也發(fā)帖證明了這個音訊。
這個內(nèi)部推理模型的得分足夠高,在本年的IOI線上比賽中,和人類一同排名位列第6,與其他AI排名則是第1。

Sheryl Hsu表明,這次內(nèi)部模型參加了IOI的在線AI比賽項目,總共330位參賽選手。
前5位都是人類。
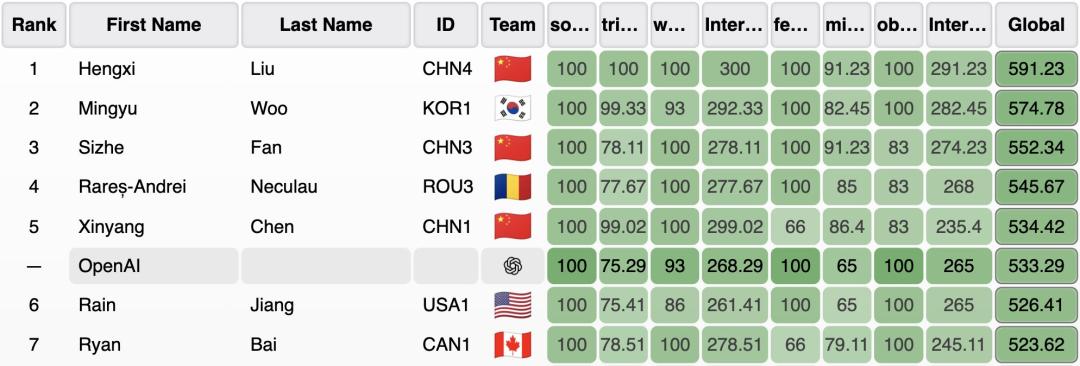
此次比賽,AI和人類參賽者相同,相同的5小時時刻約束,以及最多50次的提交約束次數(shù)。
而且,和人類相同,這個推理體系沒有「聯(lián)網(wǎng)」,也沒有亞洲色大成網(wǎng)站www在線流暢「RAG」查找,只能拜訪根本的終端東西。
這個推理模型并沒有針對IOI進行特別練習(xí)。
也便是說,除了讓模型連接到IOIAPI外,剩余的一切都靠AI自己推理。
其實上一年,OpenAI就參加過IOI比賽,其時以稍微低于銅牌分?jǐn)?shù)線的成果收尾。
只是曩昔一年時刻,推理模型的排名就從第49百分位躍升到第98百分位。

OpenAI內(nèi)部推理模型-IOI金牌團隊
不過,就在該音訊發(fā)布沒有多久。
馬斯克的Grok也來攪局了!
首要要清晰的是,這個「內(nèi)部推理模型」并不是To C的模型,除了OpenAI內(nèi)部,沒有人可以拜訪。
那像現(xiàn)在最尖端的商業(yè)模型,在IOI上體現(xiàn)怎么?
答案是:不忍目睹。
依據(jù)Vals AI的測驗成果,現(xiàn)在能在IOI取得搶先的商業(yè)模型,居然是Grok 4。

首要,現(xiàn)在一切的頂尖模型都存在顯著缺乏,沒有一個模型能在恣意一年的比賽中取得獎牌。
Grok 4以26.2%的準(zhǔn)確率搶先,隨后是GPT-5、Gemini 2.5 Pro和Claude Opus 4.1。
Vals AI經(jīng)過其揭穿端點進行測驗,一切商業(yè)模型在IOI上仍有很大的改善空間。
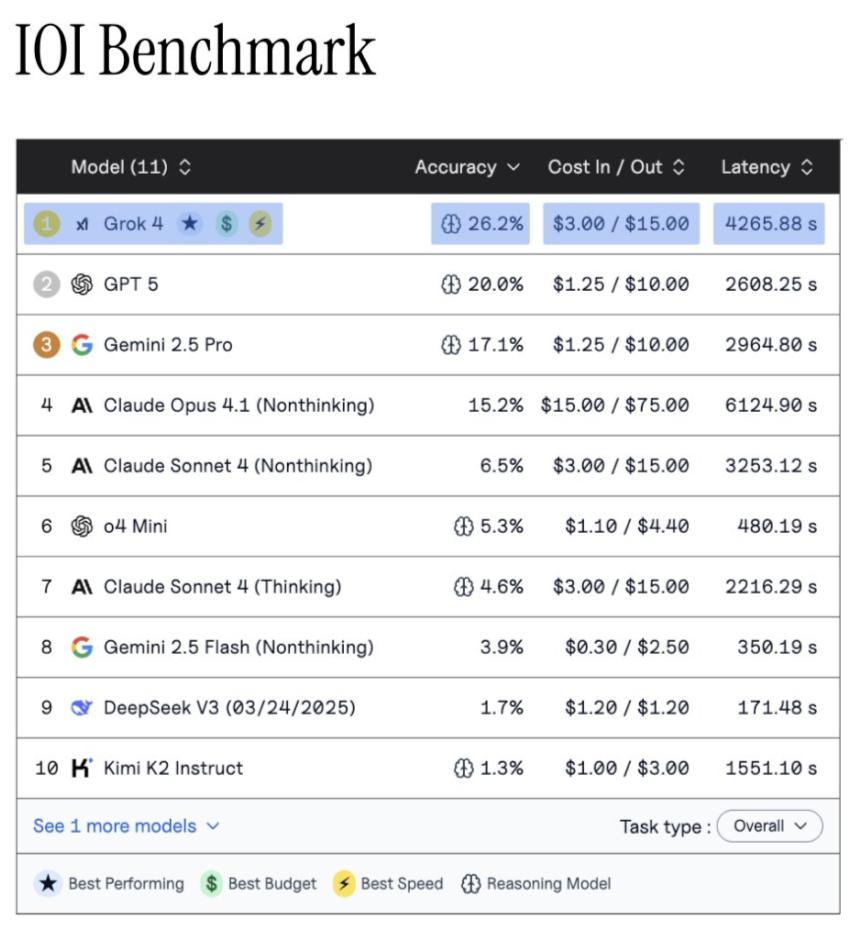
此外Vals AI這次測驗中發(fā)現(xiàn),「貴便是好」的道理也適用于大模型范疇。
只要每道問題超越2美元的貴重模型,才干取得有意義的體現(xiàn)。

也便是說,OpenAI試驗室里的那個推理模型,要遠遠強過現(xiàn)在大眾可以接觸到的商業(yè)模型。

這或許給人們帶來許多遙想,現(xiàn)在最頂尖試驗室中的最先進的AI技能間隔大眾還有多遠?
這引發(fā)了許多猜想和評論。
從IMO金牌鬧劇中可以看到,巨子們關(guān)于這種「搶先地位」的尋求十分強。
谷歌Gemini為了給自己正名為「首個取得IMO金牌的AI模型」,乃至有組委會亞洲色大成網(wǎng)站www在線流暢出頭宣告「OpenAI的宣告」是無效的。
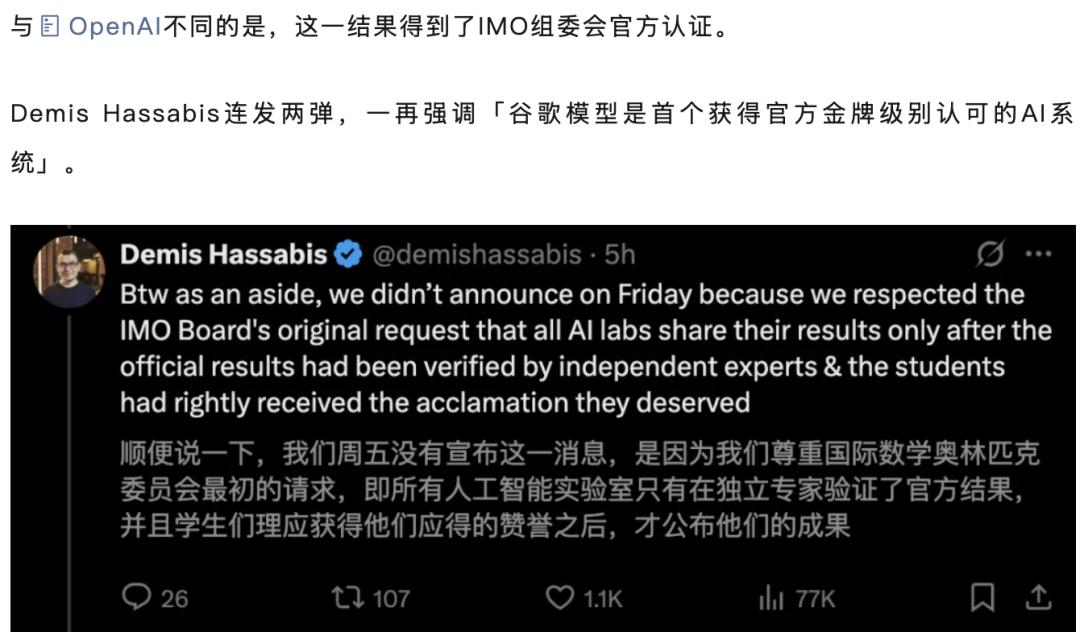
乃至還有OpenAI被曝IMO金牌造假,陶哲軒揭穿內(nèi)情的橋段。
現(xiàn)在GPT-5剛剛發(fā)布,OpenAI就立刻宣告IOI金牌,可以猜測,這應(yīng)該便是給后來的Gork 5和Gemini 3等模型預(yù)備的應(yīng)戰(zhàn)。
為何OpenAI、谷歌、Anthropic、Grok等巨子們癡迷于刷榜和比賽通關(guān)?
巨子們對刷榜和比賽排名的癡迷,根本上源自AI職業(yè)的高度競賽性和技能的快速迭代。
首要,刷榜是最直接有用的營銷手法之一。
排名榜單上的搶先方位不只意味著技能優(yōu)勢,更代表了商場影響力和品牌認(rèn)可度。一旦模型在威望比賽如IMO、IOI中斬獲佳績,企業(yè)便能敏捷建立強壯的品牌形象,招引大眾重視并提高用戶信賴。
其次,AI范疇的比賽排名一般與模型的通用功能和使用潛力高度相關(guān)。無論是IMO仍是IOI,這些比賽檢測的是模型的根底推理、邏輯推演和泛化才能。
換句話說,比賽勝出代表著模型不只在特定使命上體現(xiàn)優(yōu)異,更意味著其在更廣泛的使用場景中或許具有搶先的技能優(yōu)勢。
最終,比賽勝出可以大大提高對人才和本錢的招引力。
OpenAI團隊前往玻利維亞親自參加IOI
正因如此,OpenAI、谷歌DeepMind、Meta和Anthropic等AI巨子一向熱衷于在比賽上彼此比賽,每一次榜單的變化都或許影響AI職業(yè)未來的格式。
那么,誰是地表最強AI?
或許這個競賽會一向繼續(xù)到咱們完成AGI的那天吧。
參考資料
https://x.com/SherylHsu02/status/1954966118680105150
本文來自微信大眾號“新智元”,作者:定慧,36氪經(jīng)授權(quán)發(fā)布。