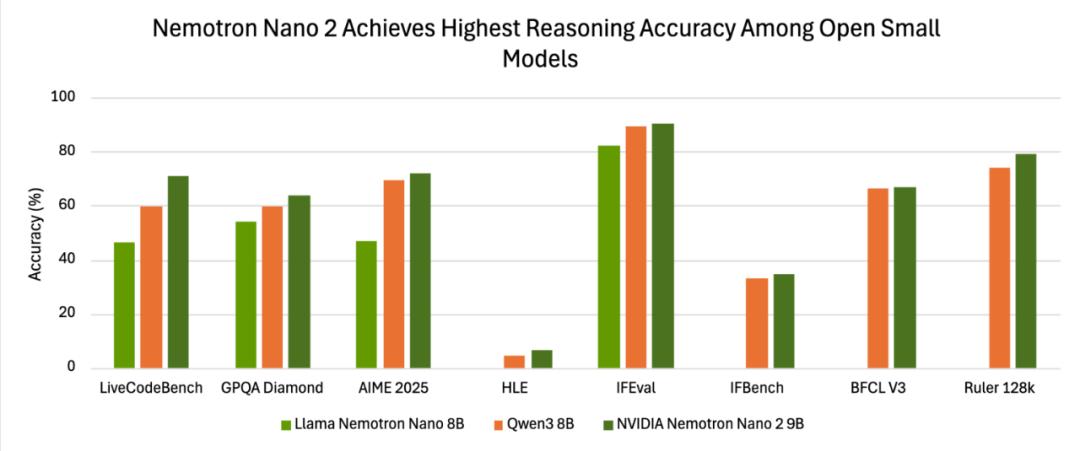
在 AI 范疇,小型模型正迎來歸于它們的高光時間。從 MIT 子公司 Liquid AI 發布的可裝入智能手表的新 AI 視覺模型,到能在谷歌智能手機上運轉的模型,小型化、高效化已成為明顯趨勢。而現在,英偉達也強勢參加這一浪潮,帶來了全新的小言語模型(SLM)——Nemotron - Nano - 9B - v2。這款模型不僅在選定基準測驗中到達同類最高功用,更具有讓用戶自在敞開和封閉 AI “推理” 的共同才能,為 AI 運用拓荒了新的幻想空間。
“小” 模型從邊際玩具到出產主力
曩昔三個月,AI 圈的 “迷你軍團” 連續亮劍,掀起了一場無聲的革新。MIT 子公司 Liquid AI 推出的視覺模型,細巧到能輕松裝入智能手表,讓可穿戴設備的智能體會邁入新臺階;谷歌則將 Gemini-Nano 成功塞進 Pixel 8 手機,讓移動端 AI 才能完成質的騰躍;當今,英偉達帶著 90 億參數的 Nemotron-Nano-9B-v2 上臺,將其布置在單張 A10 GPU 上,再次改寫了人們對小型模型的認知。
這絕非一場 “小而美” 的技能炫技,而是一次對本錢、功率與可控性的精準平衡試驗。正如英偉達 AI 模型后練習主管 Oleksii Kuchiaev 在 X 上直言:“120 億參數精簡到 90 億,便是專門為了適配 A10—— 那但是企業布置中最常見的顯卡。亞洲中文字幕在線第5頁”
一句話:參數巨細不再是衡量模型好壞的 KPI,出資回報率(ROI)才是硬道理。
把思想鏈條做成可計費功用
傳統大模型的 “黑盒思想” 一直是企業運用的痛點 —— 一旦觸發長期推理,token 賬單就好像脫韁野馬般失控。而 Nemotron-Nano-9B-v2 給出的解法簡略直接且高效:
在 prompt 中參加 /think,模型便會啟用內部思想鏈,像人類考慮相同逐漸推導;參加 /no_think,則會直接輸出答案,省去中間環節;體系級的 max_think_tokens 功用,好像 AWS 的 CPU credit 機制,能為思想鏈設定預算,精準操控本錢。
現場實測(官方陳述)數據更能闡明問題:
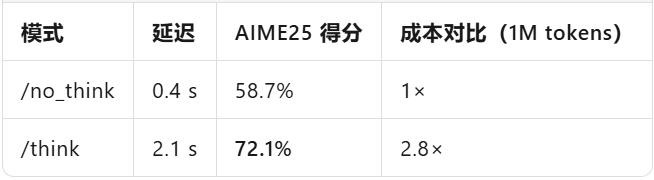
一句話:把「推理」從默許才能變成可選項,企業第一次能夠像買云硬盤相同,按考慮深度付費。
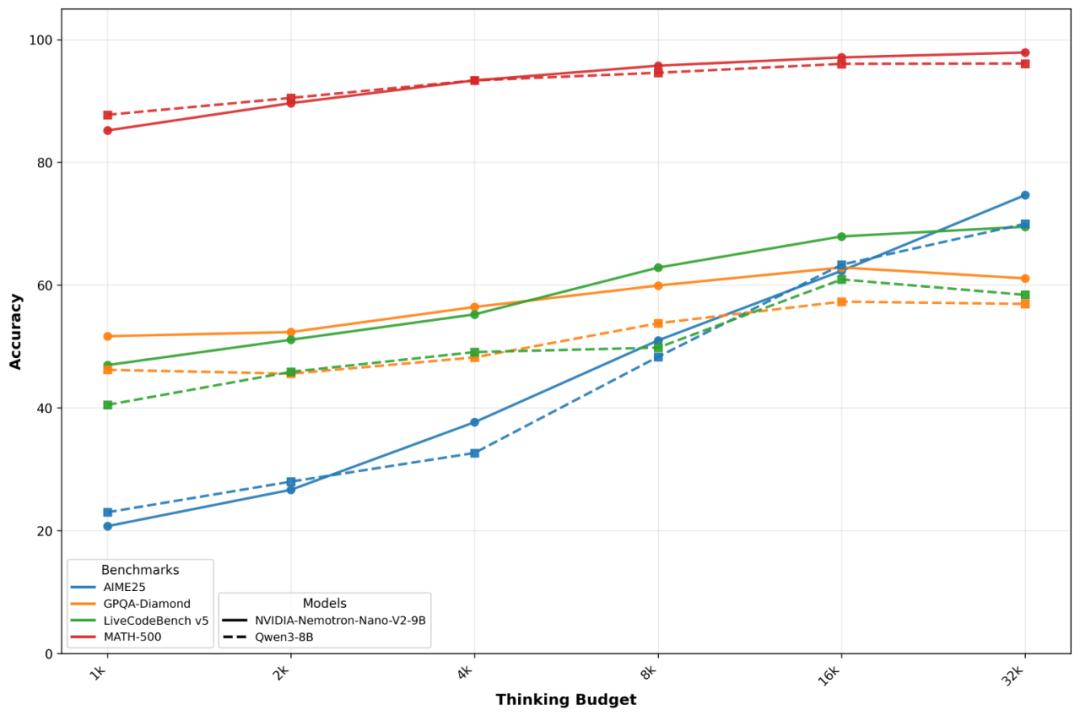
Transformer 的「省油」補丁
為何 9B 模型能在長上下文里打平 70B?答案藏在Mamba-Transformer 混合架構里:
用 Mamba 狀況空間層替換 70% 的注意力層,顯存占用 ↓ 40%;
序列長度與顯存呈線性聯系,而非平方爆破;
128k token 實測吞吐量比同尺度純 Transformer高 2.3×。
一句話:Mamba 不是替代 Transformer,而是把它改形成省油的混動引擎。
商業核彈:寬松答應證 + 零門檻商用
英偉達此次在答應協議上的行動可謂 “商業核彈”,做到了 “三不要”:
不要錢:無版稅、無收入分紅,企業無需為運用模型付出額定費用;不要商洽:直接下載即可商用,省去了繁瑣的協作洽談流程;不要法務焦慮:僅要求恪守可信 AI 護欄和出口合規,降低了企業的法令危險。亞洲中文字幕在線第5頁
比照 OpenAI 的分級答應、Anthropic 的運用上限,Nemotron-Nano-9B-v2 簡直成了 “開源界的 AWS EC2”—— 拿來就能上線掙錢,極大地降低了企業的運用門檻。
場景切片:誰最早獲益?
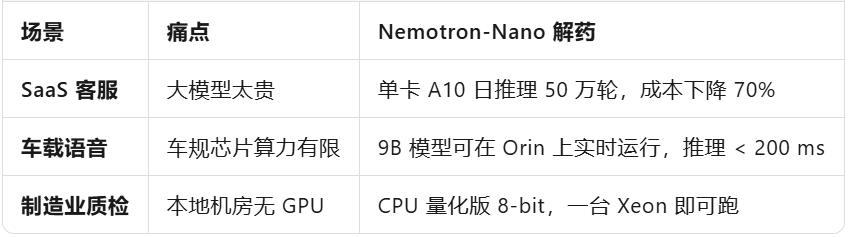
一句話:任何邊際/私有化場景,都多了一張「滿足聰明又付得起」的牌。
AI 的「精算年代」正式開幕
曩昔四年,咱們見證了 scaling law 的魔法:參數 × 算力 = 功用。當今日,Nemotron-Nano-9B-v2 用 90 億參數告知咱們:架構 × 操控 × 答應證 = 可繼續的 AI 經濟。
當 Liquid AI 把模型塞進手表,當英偉達把推理做成開關,“小” 不再是技能上的退讓,而是通過克勤克儉后的最優解。
下一次融資路演,創業者們或許不會再說 “咱們比 GPT-4 更強”,而是會自傲地聲稱:“咱們用 1/10 的算力,做出了 90% 的作用,而且還能掙錢。” 這標志著,AI 的 “精算年代” 已正式拉開帷幕。
本文來自微信大眾號“山自”,作者:Rayking629,36氪經授權發布。