昨晚,AI圈又迎來一次深夜“突襲”。
DeepSeek(深度求索),在未開發布會的情況下,悄然上線了其全新的V3.1版別模型。

雖然低沉,但其透露出的功用和參數卻可謂“王炸”,敏捷在技能圈和出資圈引發熱議。揭露信息與社區實測顯現,這次更新的亮點極端杰出:
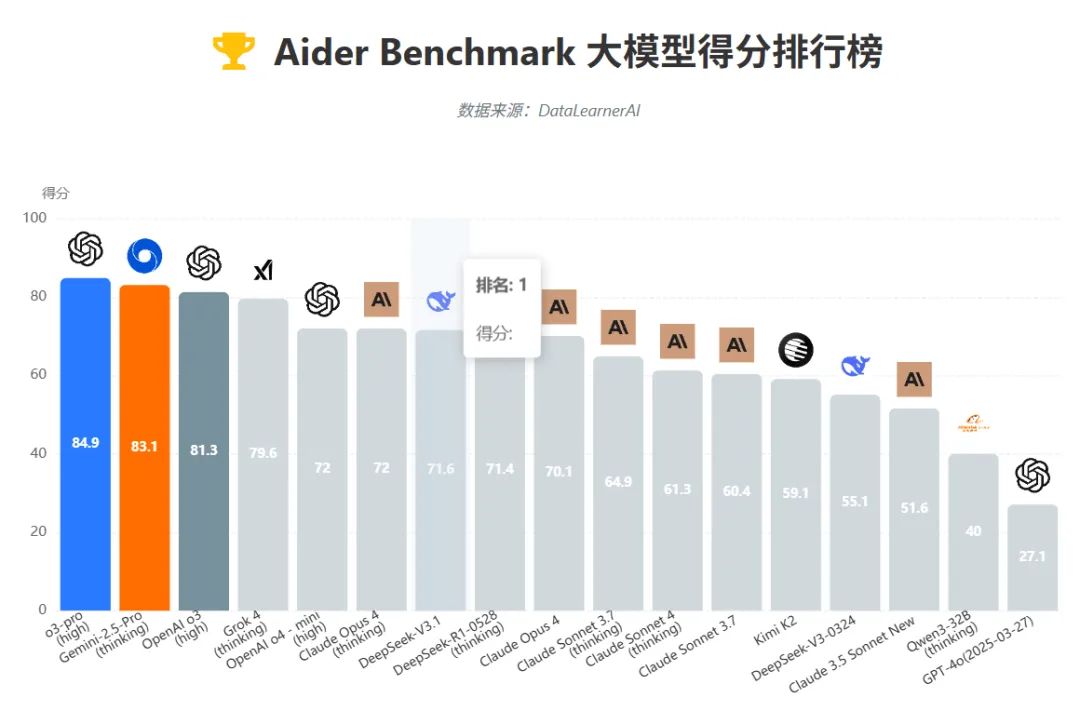
編程才能逾越Claude 4 Opus: 在威望的Aider編程基準測驗中,V3.1以71.6%的高分,逾越了此前公認的編程強者ClaudeOpus 4,登頂開源模型第一。
極致的本錢優勢: 完結一次完好的編程使命,本錢僅需約1.01美元,比功用稍遜的Claude Opus 4廉價了68倍!
架構立異信號:線上模型悄然去除了“R1”(代表深度考慮)的標識,并新增了search和think等特別Token,引發了職業對DeepSeek未來或許選用“混合架構”的廣泛猜測。

- <|search_begin|>(id:128796)<|search_end|>(id:128797)(id:128798)(id:129899)
揭露的評測數據是“曩昔時”,而出資決策永久面向“未來時”。當社區和媒體還在為V3.1的功用跑分喝彩時,實在敏銳的本錢現已開端對AI賽道的底層邏輯和未來格式進行壓力測驗。
以下四個問題,或許比單純的跑分數據更能決議未來幾個季度AI賽道的資金流向,也是咱們以為您最需求取得一手洞見的范疇。
出資者有必要考慮的四大“非一致”問題
1. 開源 vs 閉源的結局之戰:天平正在歪斜,仍是進入“混合態”?
DeepSeek V3.1的呈現,讓“開源追逐閉源”的敘事變得愈加詳細。但簡略的“追逐”二字,掩蓋了更雜亂的工業演進。專業出資者需求探求的是:
護城河的消解與重構: 曩昔,商場遍及以為閉源巨子(OpenAI, Anthropic)的護城河在于“數據飛輪+頂尖人才+極致的模型規劃”。現在,當Llama , Mistral 以及DeepSeek 在特定才能(如編程、數學)上完成反超,
咱們有必要從頭評價這條護城河的實在寬度。閉源的中心優勢是否現已從“通用智能的肯定搶先”,縮短為“多模態、超長上下文等前沿功用的‘時刻窗口’優勢”? 這個時刻窗口有多長?這對閉源模型的估值邏輯和API定價才能會構成多大的長時間限制?
企業選用的“混合形式”成為干流: 越來越多的企業正在選用一種務實的“混合形式”:端側和私有化布置,優先運用經過微調的、更可控的開源模型來處理敏感數據和高頻使命;而在公有云上,則調用最強壯的閉源模型來處理最雜亂的、非中心數據的使命。麻豆果傳媒
這種“混合態”將怎么重塑云廠商的AI服務格式? 這對Snowflake, Databricks這類企圖構建“數據+模型”一體化途徑的公司的戰略是利好仍是利空?出資者應怎么在這種趨勢下,從頭評價整個AI PaaS層的價值散布?

2. “混合架構”的猜測:是下一代技能護城河,仍是高檔的“本錢游戲”?
DeepSeek去除“R1”標識和新增特別Token的行為,被職業遍及解讀為或許在探究“混合推理”或“模型路由”架構。這并非簡略的技能迭代,其背面是深入的商業考量。

對推理本錢的“降維沖擊”:“混合架構”的中心思維,是用一個輕量級的“調度模型”來判別用戶懇求的雜亂程度,然后將其分發給最合適的“專家模型”(大、中、小模型)來處理,防止“殺雞用牛刀”。
這種架構能否將大模型推理的單位經濟效益(Unit Economics)提高一個數量級? 假如能,這將直接沖擊以供給通用大模型API為首要商業形式的公司。更重要的是,這對下流AI使用的本錢結構意味著什么?
對硬件需求的結構性影響:當時“越大越好”的模型范式,直接推進了對NVIDIA H100/B200等尖端GPU的巨量需求。但假如“混合架構”成為干流,是否意味著未來數據中心將需求更多樣化的算力組合,例如很多用于“調度模型”和“小模型”的低本錢推理芯片?這是否會為NVIDIA之外的其他芯片廠商(如AMD, Intel)以及專門從事推理優化的公司(如Groq)翻開新的商場窗口? 對NVIDIA的長時間出資邏輯,是否需求參加這一新的變量進行考量?
3. 極致性價比:AI使用層的“寒武紀大迸發”何時到來?
當模型才能趨于SOTA,而推理本錢下降60-70倍時,最直接的影響將發生在AI使用層。這不僅是突變,更或許引發突變。
商業形式的根本性革新:此前,昂揚的API調用本錢是許多AI原生使用(尤其是Agent類使用)無法大規劃商業化的中心桎梏。現在,本錢的急劇下降,是否意味著AI使用的商業形式能夠從“按次調用”或“按Token計費”,轉向更被企業承受的“按月訂閱(SaaS)”形式? 這將極大提高AI使用的營收穩定性和商場天花板。
出資者應該重視哪些賽道的上市公司,最有或許獲益于這場“本錢革新”,然后完成盈余猜測的“戴維斯雙擊”?
價值鏈的贏利再分配:假如根底模型(IaaS/PaaS層)由于開源的競賽而逐步“商品化”,那么價值鏈中的贏利重心是否會加快向上游的“使用層”和“處理方案層”搬運?實在的護城河不再是具有哪個模型,而是誰具有“高質量的私有數據”、“對特定職業工作流的深入了解”以及“強壯的企業出售途徑”。
在這個邏輯下,咱們應怎么從頭評價那些手握海量用戶和數據的傳統軟件巨子(如Microsoft, Adobe, Salesforce)與新式AI原生使用創業公司之間的競賽格式?
4. 功用之外:下一個決議輸贏的中心戰場在哪里?
跟著模型在各大基準測驗榜單上的排名日益“內卷”,單純的功用分數現已不再是決議一個模型或一家公司商業勝敗的僅有要素。下一個階段的競賽,將在更蔭蔽、更關乎麻豆果傳媒企業實踐落地的維度打開。
“企業級安排妥當度”:這是一個綜合性概念,包含了模型的穩定性、可猜測性、安全性以及合規性(如數據隱私、GDPR等)。一個在開源社區備受好評的模型,未必能經過大型金融或醫療機構的合規檢查。
未來,誰能首先供給一整套包含模型、東西鏈和合規處理方案的“企業級套件”,誰就或許把握敞開萬億級企業商場的鑰匙。
“筆直范疇”的深度優化與生態構建:通用大模型(GWM)無法完美處理一切問題。實在的商業價值迸發,往往來自于與特定職業(如法令、金融、生物醫藥)深度結合的“筆直范疇大模型”(Vertical LLM)。
例如,彭博練習的BloombergGPT。競賽的焦點將從“誰的模型更大”,轉向“誰的模型更能了解特定職業的‘黑話’和雜亂邏輯”。 與此同時,環繞這些筆直模型的生態系統——包含開發者東西、API接口、社區支撐——將成為確定客戶、構建長時間壁壘的要害。

結語
DeepSeek V3.1的發布,就像一顆投入湖面的石子,其實在的含義不在于石子自身,而在于它所激起的、一圈圈向外分散的工業漣漪。

這些漣漪所觸及的,正是二級商場出資中最中心的變量:競賽格式、本錢結構、商業形式和長時間護城河。
而這些問題的答案,無法從任何一份揭露的研報或新聞稿中找到。它們深藏在一線工業的動態之中,存在于那些正在親手“推進革新的人”的考慮里。
本文來自微信大眾號“硅兔君”(ID:gh_1faae33d0655),作者:硅兔君,36氪經授權發布。