“我真的厭惡了看到那些急于求成的科技草創公司,為了巴結風投而在數據上說謊,還貼上‘SOTA’的標簽。”有網友吐槽。
工作源于高人氣開源智能體回憶項目 Mem0 在本年 4 月底發布的一篇論文。論文中,該項目團隊為可擴展的、以回憶為中心的架構 Mem0 提出了增強版別,并宣稱在 LOCOMO 上打敗了所有人,其間,Mem0 在 “LLM-as-a-Judge” 方針上相較于 OpenAI 提高了 26%。(論文地址:https://arxiv.org/abs/2504.19413)
當地時刻 8 月 13 日, 另一個高人氣的智能體回憶結構 MemGPT 的開創團隊 Letta AI ,其聯合開創人兼 CTO Sarah Wooders 對此揭露指控:
幾個月前,Mem0 發布了 MemGPT 的基準測驗數據,并宣稱在回憶方面達到了 “SOTA” 水平。
奇怪的是,我徹底不知道他們到底是怎樣跑這個基準測驗的,假如不對 MemGPT 做嚴重修正,這個測驗底子無法完結(他們沒有回應咱們關于試驗詳細運轉辦法的問詢)。
arXiv 并不是經過同行評定的渠道,所以不幸的是,近年來公司能夠隨意發布任何他們想要的“研討”成果來做市場營銷。
咱們很輕松就用一些簡略的文件體系東西逾越了他們的基準數據——這也闡明這個基準測驗自身并沒有太大含義。
“Mem0 宣稱他們在 LOCOMO 上打敗了所有人,但成果發現他們徹底把競爭對手的完結搞砸了。然后還用這些糟糕的成果來證明自己的優勢。比及 Letta 和 Zep 按正確辦法跑了基準測驗后,兩者的得分都比 Mem0 的最佳成果高出 10%。”網友點評道,“這個職業里的‘空氣產品’多到離譜。我了解為了拿到風投,企業會夸張功用,但在科研論文里說謊實在是可悲。”
兩個“頂流”興起
Mem0 和 Letta 的誕生都是為了處理大模型的長時刻回憶問題。
自 GPT-4 面世以來,大模型一向受限于固定的上下文長度。沒有長時刻回憶,大模型和智能領會面對顯著約束:它們會忘記信息,無法跟著時刻學習和改善,而且在長時刻、雜亂的使命中會失掉方針。
為此,在 2023 年,加州大學伯克利分校(UC Berkeley)的研討團隊提出的一種創新式體系 MemGPT, 學習傳統操作體系(OS)的理念,引進了智能體的回憶辦理,經過構建回憶層級,讓智能體主動辦理哪些信息保留在即時上下文(中心回憶)中、哪些存儲在外部層(對話回憶、歸檔回憶和外部文件),以便按需檢索。這樣,智能體能夠在固定的上下文窗口內堅持無限的回憶容量。
MemGPT 的研討敏捷引起社區重視,MemGPT 論文的帖子在 Hacker News 主頁上停留了 48 小時,開源后已累積 17.8k stars。
跟著開源項目的推進,團隊建立了名為 Letta 的公司,繼續保護 MemGPT 開源結構,并推進其商業化和工程化落地。本來的 MemGPT 也晉級成了 Letta。
這家由伯克利博士生 Sarah Wooders 和 Charles Packer 創立的 AI 草創公司備受等待。Letta 取得了由 Felicis 的 Astasia Myers 領投的 1000 萬美元種子資金,本輪估值為 7000 萬美元。此外,還得到了人工智能范疇一系列天使投資人的支撐,其間包含谷歌的 Jeff Dean、Hugging Face 的 Clem Delangue、Runway 的 Cristóbal Valenzuela 和 Anyscale 的 Robert Nishihara 等。
現在,許多智能體體系都完結了 MemGPT 的規劃。
Mem0 則是由印度工程師 Taranjeet Singh 和 Deshraj Yadav 建立,源于他們構建開源檢索增強生成 (RAG) 結構 Embedchain 的經歷,該結構下載量逾越 200 萬次。
依據 YC 的介紹,Singh 曾作為首位增加工程師參加 Khatabook(YC S18),并敏捷晉升為高檔產品司理。他的軟件工程職業生涯始于 Paytm(印度的 PayPal),親歷了其敏捷興起成為眾所周知的品牌。他開發了一款由 AI 驅動的教導運用,曾在 Google I/O 上露臉。他與 Deshraj 一起創立了 EvalAI,這是一個開源的 Kaggle 代替渠道,GitHub 上取得了 1.6K stars。他還創立了首個 GPT 運用商鋪,用戶規劃打破 100 萬。
Yadav 則廣泛重視人工智能和機器學習基礎設施范疇,曾領導特斯拉主動駕馭的 AI 渠道,亞洲Av碼高清在線支撐特斯拉全主動駕馭開發中的大規劃練習、模型評價、監控和可觀測性。在此之前,Deshraj 在喬治亞理工學院完結碩士論文時創立了開源機器學習渠道 EvalAI,并在 CVPR、ECCV、AAAI 等上宣布過論文。
Mem0 以為,單純地擴展模型的上下文窗口只會推遲問題的產生,模型會變得更慢、本錢更高,而且仍然會疏忽要害細節。團隊挑選經過一個通用、可擴展的回憶架構來處理問題,Mem0 充當了 AI 運用程序和大模型之間的回憶層,能夠動態地從用戶對話中提取、整合和檢索重要信息。
Mem0 供給輕量級的回憶層 API 和向量檢索,開源不到一天就取得了 9.7k stars,現在已累積 38.2k stars。Netflix、Lemonade 和 Rocket Money 等安排已選用 Mem0 來增強其 AI 體系的長時刻回憶才能。
此外,業界還呈現了多種專用東西,將“回憶”作為可插拔的服務,為智能體供給存儲與檢索信息的才能,常見辦法包含運用常識圖譜或向量數據庫等計劃。
獨自評價這些回憶東西的有用性極端困難。智能體的回憶質量往往更多取決于底層智能體體系辦理上下文和調用東西的才能,而不是回憶東西自身。比方,即使一個查找東西理論上功用更強,但假如智能體無法有用運用它,例如提示詞規劃差或練習數據中短少相關示例,它在回憶場景下的體現也不會好。
因而,回憶東西的評價首要會集在類似 LoCoMo 這樣的檢索基準測驗,而非真實的智能體回憶才能。
LoCoMo 是一個從長對話中進行檢索的問答基準,專門用于評價大模型長時刻對話回憶才能,由 Snap Research 團隊推出。每個樣本包含兩名虛擬說話者和一份 AI 生成的帶時刻戳的對話記載,使命是答復關于說話者或對話中呈現的現實問題。
不合在哪里?
在 4 月底的論文中,Mem0 團隊在之前的基礎上引進了依據圖的回憶表明,來增強聯系建模才能。
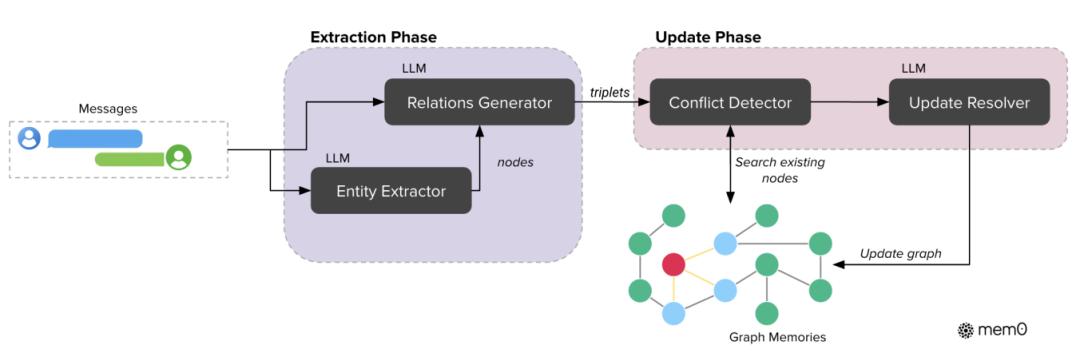
之前,Mem0 的提取階段處理音訊和前史上下文以創立新的回憶;更新階段則將提取出的回憶與類似的現有回憶進行比對,經過東西調用機制履行相應操作。數據庫作為中心存儲庫,供給處理所需的上下文,并存儲更新后的回憶。
引進依據圖的回憶后,提取階段運用大模型將對話音訊轉換為實體和聯系三元組;更新階段在將新信息整合到已有常識圖譜時,選用抵觸檢測與處理機制。
在實踐完結中,Mem0g 運用 Neo4j 作為底層圖數據庫 ,依據大模型的提取器和更新模塊并憑借具有函數調用才能的 GPT-4o-mini,從非結構化文本中進行結構化信息提取。經過將依據圖的表明與語義嵌入以及依據大模型的信息提取相結合,Mem0 取得了雜亂推理所需的結構豐厚性和自然語言了解所需的語義靈敏性。
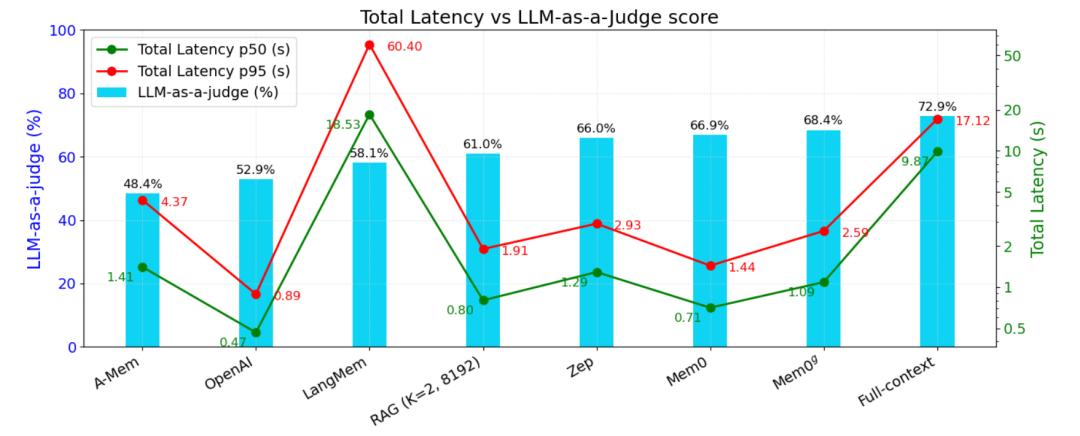
在 LOCOMO 基準測驗中,Mem0 表明其繼續逾越六種搶先的回憶辦法,體現為:呼應準確率比 OpenAI 的提高 26% 、推遲比全上下文辦法下降 91%、token 運用量節約 90%。
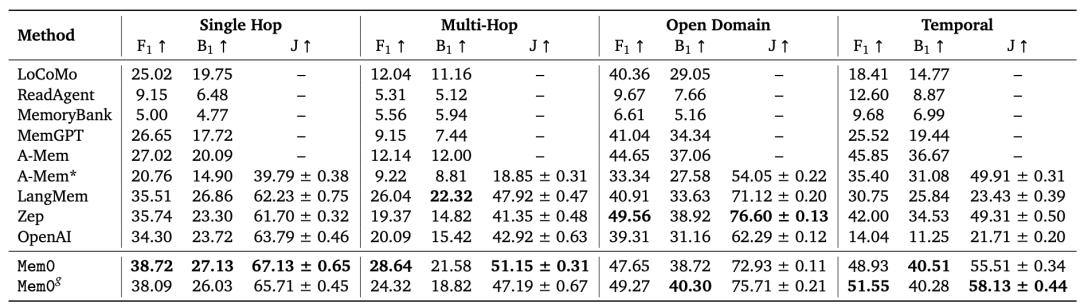
下圖是不同回憶辦法在 p50 和 p95 的總呼應推遲比較,其間包含了大模型推理在內的推遲。
Mem0 團隊以為,在 AI 智能體布置中,依據詳細推理場景靈敏調整回憶結構很重要:
Mem0 的稠密回憶管道拿手快速呼應、簡略查詢,最大極限削減 token 耗費與核算開支;而改善后,Mem0 的結構化圖表征能明晰解析雜亂聯系,支撐雜亂事情排序和豐厚上下文整合,一起不獻身實踐功率。兩者合力構建了一個多功用的回憶東西包,能夠習慣多樣的對話需求,并具有大規劃布置才能。
6 月時分,Sarah 在 GitHub 上問詢 Mem0 是怎么取得 MemGPT 的相關數據的,但沒有回應。
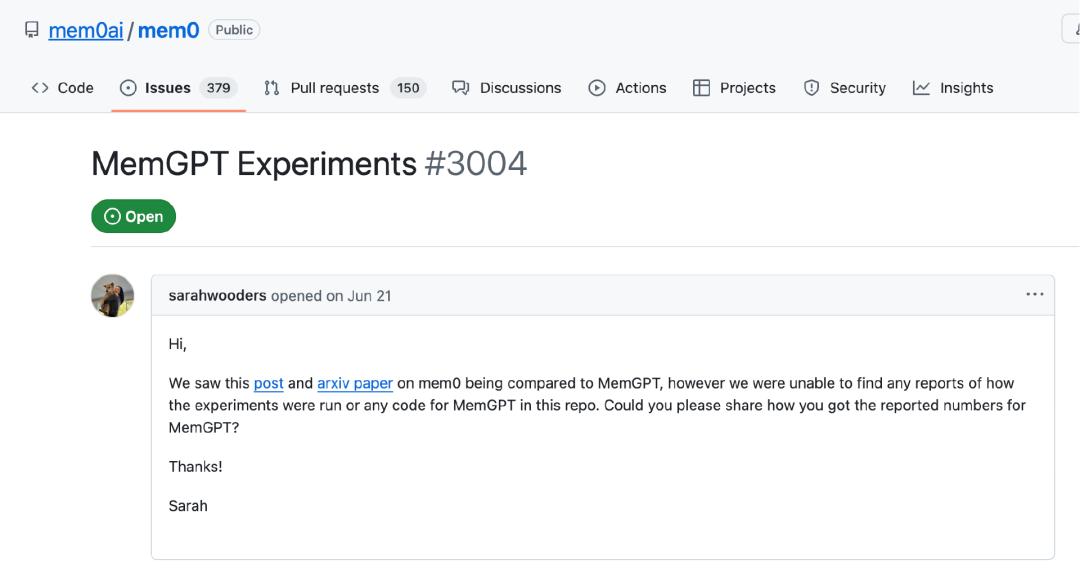
“有一個回憶東西廠商 Mem0 發布了有爭議的成果,宣稱在 LoCoMo 上運轉了 MemGPT。但成果令人困惑,因為咱們(MemGPT 的原團隊)無法找到不進行大規劃代碼重構就將 LoCoMo 數據灌入 MemGPT/Letta 的辦法。Mem0 并未回應咱們對其基亞洲Av碼高清在線準測驗核算辦法的弄清懇求,也沒有供給支撐 LoCoMo 數據回填的修正版 MemGPT 完結。”Letta 表明。
當地時刻 8 月 12 日,Letta 發文稱,Letta 在 LoCoMo 上僅經過將對話前史存儲在文件中(而不是運用專門的回憶或檢索東西),就達到了 74.0% 的準確率。這表明:
之前的回憶基準測驗或許并不十分有含義;
回憶更多取決于智能體怎么辦理上下文,而不是所運用的詳細檢索機制。
Letta 表明,盡管 Letta 自身沒有原生辦法導入 LoCoMo 那樣的對話前史,但其最近為 Letta 智能體(包含 MemGPT 智能體)增加了文件體系功用。“咱們獵奇,假如僅僅把 LoCoMo 的對話前史放進一個文件,而不運用任何專用回憶東西,Letta 的體現會怎么。”
當文件被掛載到 Letta 智能體后,智能體能夠運用以下文件操作東西:
- grep
- search_files
- open
- close
對話數據被放進一個文件并上傳掛載到智能體中。Letta 會主動解析并嵌入文件內容,以便進行語義(向量)查找。智能體能夠用 search_files 做語義查找,用 grep 進行文本匹配,再用 answer_question 答復問題。
為了與 MemGPT 的原試驗堅持一致,Letta 用 GPT-4o mini 作為模型。因為 GPT-4o mini 才能較弱,Letta 讓智能體部分自治,經過規矩約束其調用東西的形式:必須先調用 search_files 查找文件,再不斷查找直到決議調用 answer_question 并完畢。查找什么、查找多少次由智能體自行決議。
“這個簡略的智能體在 GPT-4o mini 和最少提示調優的情況下,就在 LoCoMo 上取得了 74.0% 的成果,顯著高于 Mem0 陳述的其最佳圖回憶版別的 68.5%。”
Letta:才能比東西更重要
Letta 以為,現在的智能體在運用東西方面十分高效,尤其是那些很或許呈現在練習數據中的東西,如文件體系操作。因而,許多本來為單跳檢索規劃的專用回憶東西,還不如直接讓智能體自主迭代查找數據來得有用。
智能體能夠生成自己的查找查詢,而不僅僅是檢索原始問題,例如將 “How does Calvin stay motivated when faced with setbacks?” 轉化為 “Calvin motivation setbacks”,而且智能體能夠繼續查找直到找到正確數據。
智能體是否“記住”了某事,取決于它能否在需求時成功檢索到正確信息。因而,更重要的是考慮智能體是否能夠有用運用檢索東西(知道何時以及怎么調用),而不是糾結于詳細的檢索機制(如常識圖譜仍是向量數據庫)。
Letta 還提出,現在智能體能夠十分高效地運用文件體系東西,在很大程度上是因為后期優化要點傾向智能體的編碼使命。一般來說,越簡略的東西越或許呈現在智能體的練習數據中,也越簡略被有用運用。盡管更雜亂的計劃(如常識圖譜)在特定范疇或許有用,但它們或許更難被 大模型(智能體)了解。
“智能體的回憶才能取決于智能體的架構、東西和底層模型。比較智能體結構與回憶東西,就像比較蘋果和橘子,因為結構、東西和模型都是能夠自由組合的。”Letta 說道。
那怎么正確評價智能體回憶才能呢?
Letta 先引薦了自家的 Letta Memory Benchmark(Letta 排行榜) 供給了同類比照(apples-to-apples),在堅持結構(現在僅 Letta)和東西不變的情況下,評價不同模型在回憶辦理方面的才能。該基準在動態上下文中即時生成回憶交互場景,然后評價智能體回憶,而不僅僅是檢索才能(如 LoCoMo)。
然后指出,另一種辦法是直接評價智能體在需求回憶的詳細使命中的全體體現。例如 Terminal-Bench,測驗智能體處理雜亂、長時刻運轉使命的才能。因為使命時刻長且需求處理遠超上下文窗口的信息,智能體能夠運用回憶盯梢使命狀況與進展。
最終,Letta 總結道,關于規劃杰出的智能體,即使是簡略的文件體系東西,也足以在 LoCoMo 這樣的檢索基準中體現優異。
參閱鏈接:
https://x.com/sarahwooders/status/1955352237490008570?s=46
https://www.letta.com/blog/benchmarking-ai-agent-memory
本文來自微信大眾號“InfoQ”,作者:褚杏娟 ,36氪經授權發布。